DataOps and Data Pipeline Automation
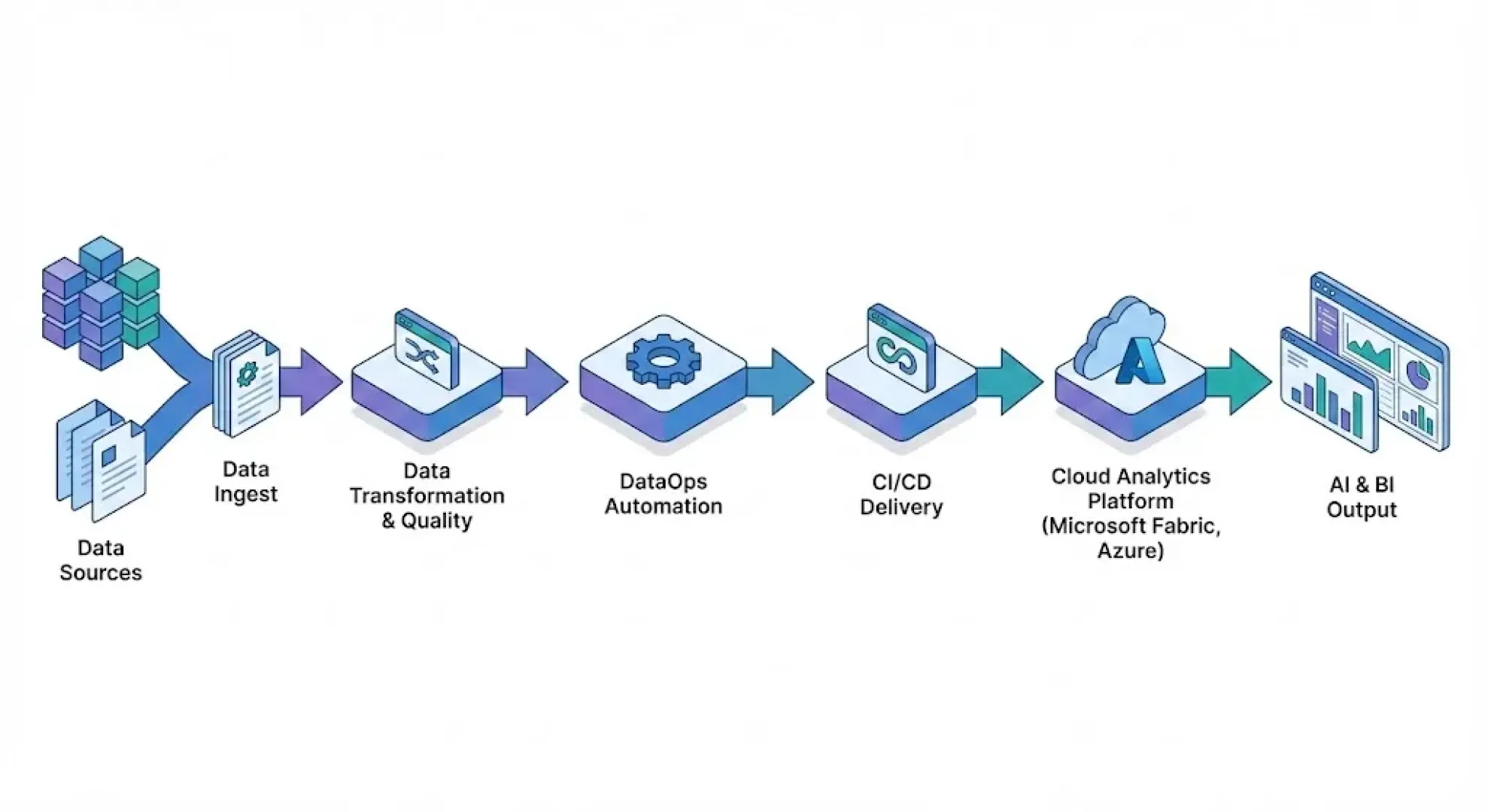
DataOps is an approach that applies the proven principles of DevOps and agile management to the data domain. Its goal is to accelerate the delivery of data outputs while increasing their reliability—through standardization, automation, and measurable quality control. In practice, DataOps brings together data engineers, analysts, data scientists, and IT operations so that data pipelines are built and run with the same discipline as modern software.
DataOps Principles and Their Connection to DevOps
Just as DevOps relies on CI/CD, code versioning, and automated testing, DataOps applies these concepts to data transformations, data models, and pipeline orchestration. Every change (e.g., a modification to transformation logic, table schemas, or quality rules) is versioned in Git, undergoes review and testing, and is only then deployed to higher-level environments. An important component is “infrastructure as code”—environments and configurations are defined in a repeatable and auditable manner, which reduces the risk of manual interventions in production.
At the same time, DataOps reinforces shared responsibility for the end-to-end data flow. From a management perspective, this means more predictable delivery of changes, fewer incidents, and a clear audit trail of what changed in the data platform and why.
Automation of the pipeline from collection to deployment
At the heart of DataOps is an automated "assembly line" for data. The pipeline typically covers data ingestion, transformation, quality validation, publication to target layers, and deployment of data products (e.g., tables for reporting, datasets for Power BI, or features for ML).
Automated quality checks are key: validation rules (schema, ranges, referential integrity, completeness) run continuously and, in case of deviations, trigger alerts, data quarantine, or a defined correction procedure. This “quality gate” protects the business from erroneous data entering reports or models.
Changes are deployed in a controlled manner via CI/CD: from development in an isolated environment, through testing and approval, to production. This allows for smaller changes to be delivered more frequently, without the risks associated with “major releases.”
Business Benefits
DataOps has four practical implications:
- Speed: shorter time from request to data output, with the option to run reports weekly or daily.
- Reliability: fewer errors thanks to automation, testing, and standards; faster detection and resolution of incidents.
- Auditability: a clear history of changes, traceability of pipeline versions and data, and improved control and governance.
- Reusability: Shared components and templates (connectors, transformations, validation rules) reduce costs and accelerate the development of new use cases.
Microsoft and Azure as a DataOps Ecosystem
Azure provides a comprehensive set of services for DataOps across the data lifecycle. Azure Data Factory (or integration capabilities within Microsoft Fabric) is often used to orchestrate data flows, enabling pipeline management, job scheduling, parameterization, and monitoring. Combined with a lakehouse approach (Microsoft Fabric/OneLake) and open formats such as Delta, robust data tiers (bronze/silver/gold) can be built with consistency and versioning capabilities.
Services such as Azure SQL and other analytical layers as needed (e.g., warehouse/lakehouse) are typically used for data storage and publication. Event-driven automation and integration are complemented by Azure Functions or Logic Apps. For development management, versioning, and release, the natural choice is Azure DevOps (Repo, Pipelines) or GitHub, where CI/CD can be set up for both infrastructure and data components.
The result is a platform where processes can be standardized from development through testing to operations—and measured using metrics such as availability, processing latency, number of incidents, and data quality.
How Data Mind Helps
Data Mind helps clients implement DataOps in a pragmatic way: from designing the architecture on the Microsoft/Azure stack, through setting up CI/CD, validation rules, and monitoring, to handing over standards to the teams that operate the solution. The goal is to bring data pipelines under the same level of control and discipline as critical software—so that data becomes a fast, reliable, and long-term sustainable foundation for reporting, advanced analytics, and AI.