Data Mesh in Practice: Implementation Using Domains
Today, large organizations often encounter the limitations of centralized data platforms. Data Mesh was therefore developed as a modern architectural approach that addresses the challenges of scaling and agility in data management through decentralized data ownership, domain-oriented organization, and self-service data infrastructure. This article explains the basic principles of Data Mesh, describes how domain-oriented architecture supports faster delivery of data products, outlines key elements for successful implementation, and compares the benefits and challenges of Data Mesh versus the traditional centralized approach. Finally, it includes recommendations for specific technologies (e.g., from the Azure ecosystem) for the practical implementation of Data Mesh..
The Basic Concept and Principles of Data Mesh
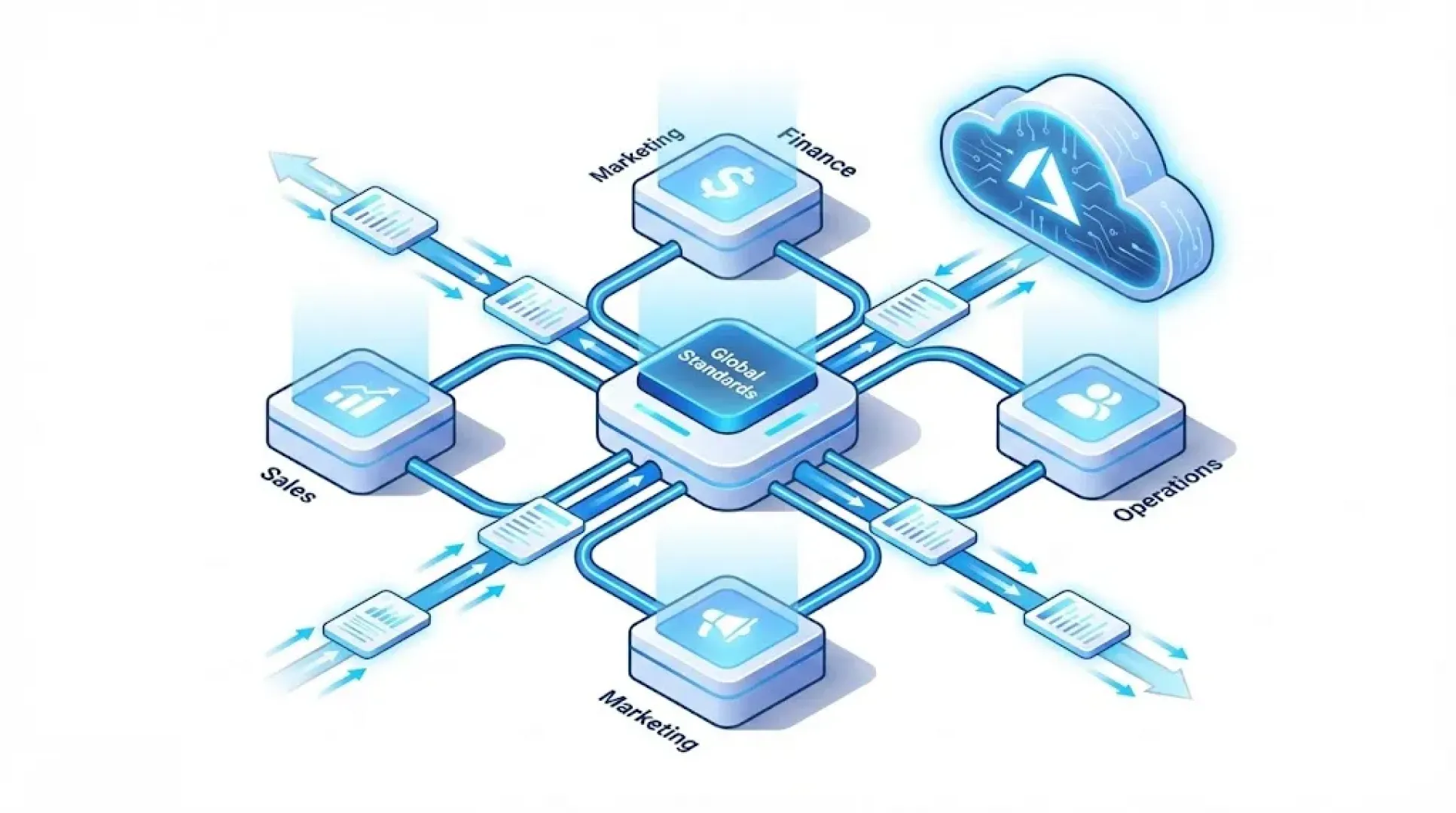
Data Mesh is a type of data platform architecture based on four key principles:
-
Domain-oriented data ownership – Responsibility for data is delegated to individual domains (e.g., departments), whose teams directly own and manage their data, ensuring that information remains closer to the source and to the people with the best contextual knowledge.
-
Data as a Product – Each dataset or service is managed as a data product with its own lifecycle, defined quality standards, documentation, versioning, and a clearly designated owner responsible for its maintenance.
-
Self-service data platform – The Central Platform Team provides a shared data infrastructure as a service, enabling domain teams to independently utilize resources such as the data lake, integration tools, and the data catalog without constant assistance from central IT.
-
Federated data governance – Decentralization requires maintaining global standards and security; therefore, representatives from domain teams, together with central data stewards, define common rules (standardized terminology, formats, quality, and security) and automatically monitor compliance with these rules across the organization.
Domain architecture for scalability and speed
Domain-oriented architecture enables each business domain to develop and deploy data products independently, thereby eliminating the bottleneck caused by a centralized data team. The parallel work of multiple teams significantly accelerates the delivery of new solutions, and because the data is closely aligned with the business, analytical outputs are more relevant and flexible.
Key components for successful implementation
In practice, implementing a Data Mesh requires several key steps. Each domain should have its own data team and clearly defined data product owners who are responsible for their quality and lifecycle. At the same time, it is necessary to build a central self-service data platform (infrastructure) and establish a federated data governance model in which domain representatives jointly define and enforce uniform standards across the organization.
Advantages and challenges compared to a centralized approach
Benefits of Data Mesh: Data Mesh delivers greater scalability and agility—decentralization eliminates bottlenecks caused by a centralized data team and enables multiple domain teams to work in parallel, thereby accelerating the delivery of data products. At the same time, clearly defined ownership of each data product increases team accountability and, consequently, the quality and reliability of data outputs.
Challenges and Risks: Without strong central coordination, there is a risk of data fragmentation and inconsistency (duplicate or unclear data). Data Mesh also places higher demands on the expertise of domain teams and requires a fundamental organizational and cultural shift—it is necessary to break down the barriers between IT and business and invest in new platforms and processes.
Technology Recommendations for Data Mesh
Although Data Mesh is primarily about an organizational model and architecture, choosing the right technologies will significantly facilitate its implementation. In a Microsoft Azure environment, Data Mesh principles can be supported using tools such as:
-
Azure Data Lake Storage & Purview – Scalable cloud data storage and a central data catalog for centralized metadata management and support for data governance across domains.
-
Azure Synapse Analytics & Databricks – Platforms for advanced data processing and analysis. Synapse offers a combination of a data warehouse and a big data environment (Spark) in one, while Databricks (using Delta Lake) enables the creation of a lakehouse architecture that integrates a data lake and a data warehouse.
-
GitOps for Data Pipelines – Applying DevOps principles to data: defining pipelines as code in a version control system (Git) and automating deployment using CI/CD, which ensures reproducibility and higher quality of data processes.
If Data Mesh is implemented correctly (including organizational changes and the right tools), it can serve as a solid foundation for a data-driven enterprise.