Data Mesh v praxi: Implementace pomocí domén
Velké organizace dnes často narážejí na limity centralizovaných datových platforem. Data Mesh proto vznikl jako moderní architektonický přístup, který řeší problémy škálování a agility práce s daty pomocí decentralizovaného vlastnictví dat, doménově orientované organizace a samoobslužné datové infrastruktury. Tento článek vysvětluje základní principy Data Mesh, popisuje jak doménová architektura podporuje rychlejší dodávání datových produktů, uvádí klíčové prvky pro úspěšnou implementaci a porovnává výhody i výzvy Data Mesh oproti tradičnímu centralizovanému přístupu. Na závěr nechybí ani doporučení konkrétních technologií (např. z ekosystému Azure) pro praktickou realizaci Data Mesh.
Základní koncept a principy Data Mesh
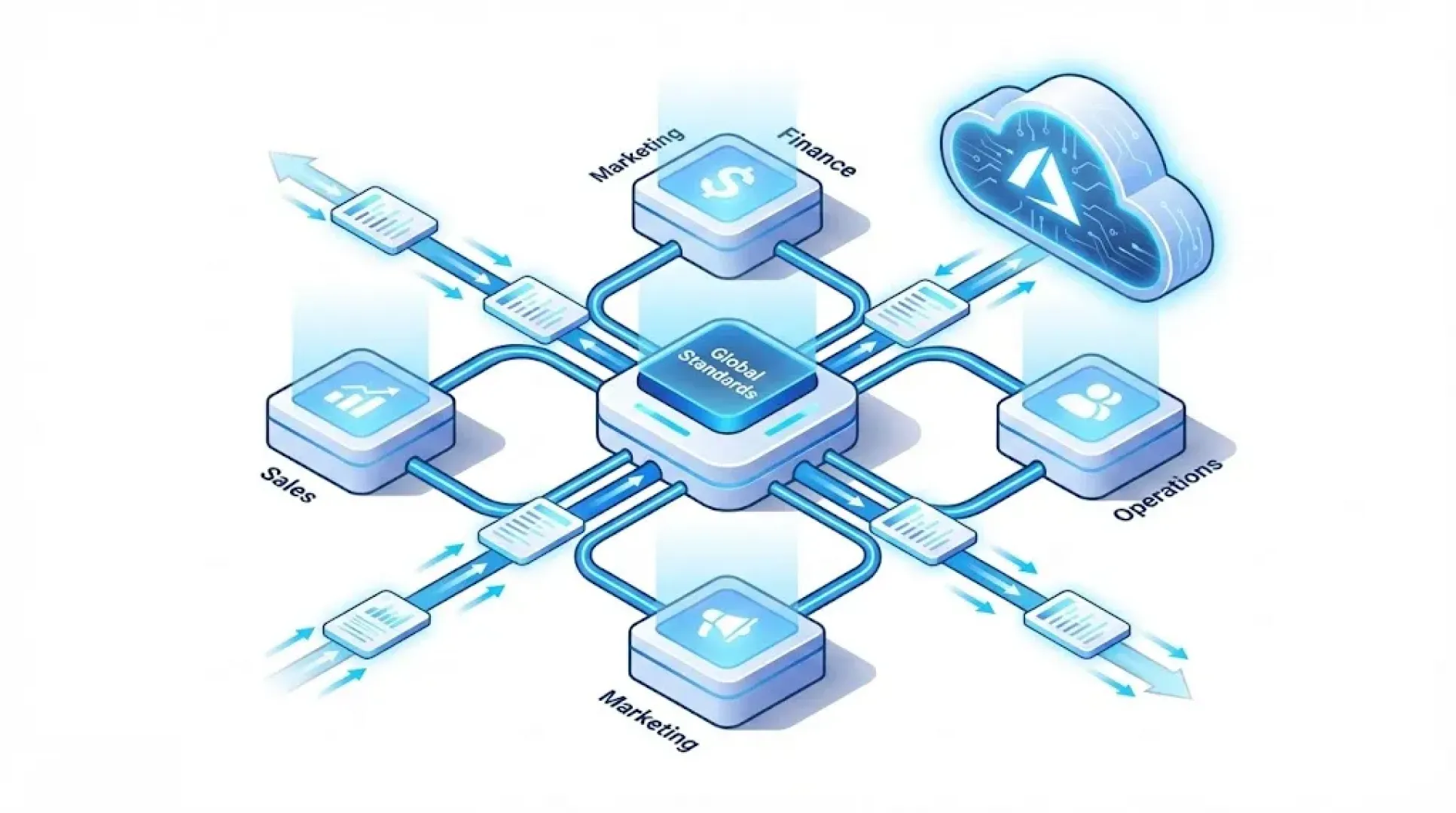
Data Mesh je typ architektury datové platformy, který staví na čtyřech hlavních principech:
-
Doménově orientované vlastnictví dat – Odpovědnost za data je delegována na jednotlivé domény (např. oddělení), jejichž týmy přímo vlastní a spravují svá data, takže informace zůstávají blíže zdroji a lidem s nejlepším znalostním kontextem.
-
Data jako produkt – Každá datová sada nebo služba se spravuje jako datový produkt s vlastním životním cyklem, definovanou kvalitou, dokumentací, verzováním a jasně určeným vlastníkem odpovědným za její údržbu.
-
Samoobslužná datová platforma – Centrální platformní tým poskytuje společnou datovou infrastrukturu jako službu, aby doménové týmy mohly samostatně využívat např. datové jezero, integrační nástroje či katalog dat bez neustálé asistence centrálního IT.
-
Federovaná správa dat – Decentralizace vyžaduje udržení globálních standardů a bezpečnosti, proto zástupci doménových týmů spolu s centrálními datovými správci definují společná pravidla (jednotné pojmy, formáty, kvalitu, zabezpečení) a automatizovaně dohlížejí na jejich dodržování napříč organizací.
Doménová architektura pro škálovatelnost a rychlost
Doménově orientovaná architektura umožňuje každé obchodní doméně vyvíjet a nasazovat datové produkty nezávisle, čímž odpadá úzké hrdlo centrálního datového týmu. Paralelní práce více týmů výrazně zrychluje dodávky nových řešení a díky blízkosti dat byznysu jsou analytické výstupy relevantnější a pružnější.
Klíčové komponenty pro úspěšnou implementaci
V praxi zavedení Data Mesh vyžaduje několik klíčových opatření. Každá doména by měla mít svůj vlastní datový tým a jasně definované vlastníky datových produktů, kteří odpovídají za jejich kvalitu a životní cyklus. Zároveň je nutné vybudovat centrální samoobslužnou datovou platformu (infrastrukturu) a nastavit federovaný model správy dat, v němž zástupci domén společně definují a vynucují jednotné standardy napříč organizací.
Výhody a výzvy oproti centralizovanému přístupu
Výhody Data Mesh: Data Mesh přináší vyšší škálovatelnost a agilitu – decentralizace odbourává úzká hrdla centrálního data týmu a umožňuje paralelní práci více doménových týmů, což zrychluje dodávky datových produktů. Zároveň jasně definované vlastnictví každého datového produktu zvyšuje odpovědnost týmů a tím i kvalitu a spolehlivost datových výstupů.
Výzvy a rizika: Bez silné centrální koordinace hrozí roztříštěnost a nekonzistence dat (duplicitní nebo nejasná data). Data Mesh také klade vyšší nároky na kompetence v doménových týmech a vyžaduje zásadní organizační a kulturní změnu – je nutné překonat bariéru mezi IT a byznysem a investovat do nové platformy i procesů.
Technologická doporučení pro Data Mesh
Ačkoli Data Mesh je především o organizačním modelu a architektuře, vhodná volba technologií výrazně usnadní jeho realizaci. V prostředí Microsoft Azure lze data mesh principy podpořit například těmito nástroji:
-
Azure Data Lake Storage & Purview – Škálovatelné úložiště dat v cloudu a centrální datový katalog pro centralizovanou správu metadat a podporu data governance napříč doménami.
-
Azure Synapse Analytics & Databricks – Platformy pro pokročilé zpracování a analýzu dat. Synapse nabízí kombinaci datového skladu a big data prostředí (Spark) v jednom, zatímco Databricks (využívající Delta Lake) umožňuje budovat lakehouse architekturu integrující datové jezero a sklad.
-
GitOps pro datové pipeline – Aplikace principů DevOps na data: definice pipeline jako kód ve verzovacím systému (Git) a automatizované nasazování pomocí CI/CD, což zajišťuje opakovatelnost a vyšší kvalitu datových procesů.
Bude-li Data Mesh správně zaveden (včetně organizačních změn a vhodných nástrojů), může se stát pevným základem datově řízeného podniku.