RAG nad firemními daty
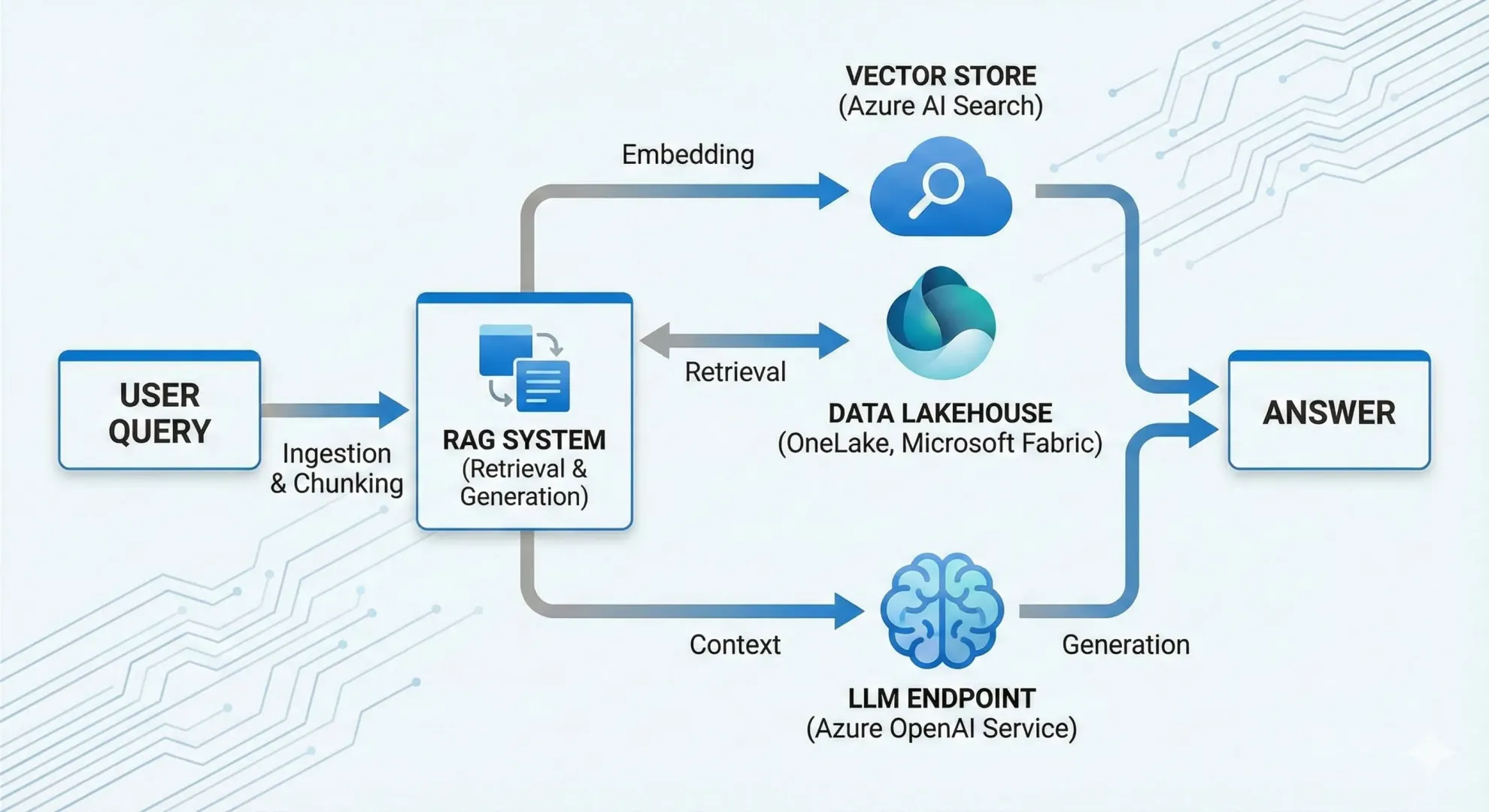
Architektura RAG v Enterprise prostředí
V éře generativní umělé inteligence čelí organizace zásadní výzvě: jak využít výkonných jazykových modelů (LLM), jako je GPT, a zároveň zajistit, aby odpovědi vycházely z uzavřeného, ověřeného firemního know-how, nikoli z veřejných tréninkových dat. Odpovědí je architektura RAG (Retrieval-Augmented Generation).
Pro technické lídry a datové architekty nepředstavuje RAG pouze aplikaci AI, ale především komplexní úlohu v oblasti Data Engineering a Data Architecture. Tento článek rozebírá technické aspekty implementace RAG v kontextu moderní datové platformy postavené na ekosystému Microsoft Azure a Microsoft Fabric.
Když se Data Science potkává s vyhledáváním
Základní problém pre-trénovaných modelů je absence kontextu o vašich privátních datech a tendence k halucinacím. RAG tento problém řeší hybridním přístupem. Proces se skládá ze dvou fází:
-
Retrieval (Získání): Na základě uživatelského dotazu systém vyhledá relevantní fragmenty informací v interní bázi znalostí (vektorová databáze, datový sklad).
-
Generation (Generování): Nalezený kontext je společně s původním dotazem předán LLM, který na jeho základě syntetizuje odpověď.
Z pohledu architektury se nejedná o „černou skříňku“, ale o sofistikovanou pipeline, která vyžaduje robustní datový základ.
Data Lakehouse jako základ pro AI
Tradiční datový sklad (Data Warehouse) byl optimalizován pro strukturovaná data a SQL dotazy. Pro potřeby GenAI, která pracuje s nestrukturovaným textem (PDF směrnice, dokumentace, transkripce hovorů, logy), je nutné přejít k paradigmatu Data Lakehouse.
V prostředí Microsoft Fabric a Azure toto sjednocení zajišťuje vrstva OneLake. Data Lakehouse umožňuje uchovávat data v jejich nativním formátu, zatímco nad nimi stavíme analytické i AI služby bez nutnosti nákladné duplikace.
Pipeline pro zpracování dat (Ingestion & Chunking)
Kvalita výstupu RAG je přímo úměrná kvalitě vstupu. Zde hraje klíčovou roli Data Engineering. Proces přípravy dat pro LLM zahrnuje:
-
Extrakce: Získání dat z různých zdrojů (SharePoint, Blob Storage, SQL DB).
-
Cleaning: Odstranění formátovacího šumu.
-
Chunking: Rozdělení textu na logické segmenty (okna), které se vejdou do kontextového okna modelu.
-
Embedding: Konverze textových chunků na vektorové reprezentace (pole čísel) pomocí embedding modelů (např. text-embedding-ada-002).
Tyto vektory jsou následně uloženy do vektorového indexu (např. v Azure AI Search), který umožňuje sémantické vyhledávání – tedy hledání podle významu, nikoli jen podle klíčových slov.
Architektura řešení v cloudu Azure
Pro enterprise nasazení je kritická bezpečnost, škálovatelnost a governance. Typická referenční architektura využívá následující komponenty:
-
Orchestrace: Frameworky jako LangChain nebo Semantic Kernel řídí tok aplikace.
-
Vector Store / Search Index: Azure AI Search, který podporuje hybridní vyhledávání (kombinace keyword search a vector search) a re-ranking výsledků pro vyšší relevanci.
-
LLM Endpoint: Azure OpenAI Service. Zde je klíčové, že data neopouštějí tenant zákazníka a nejsou využívána k dotrénování veřejných modelů.
-
Data Foundation: Microsoft Fabric pro unifikaci datových toků.
Role Data Mesh v kontextu AI
S tím, jak se AI demokratizuje napříč firmou, dává smysl aplikovat principy Data Mesh. Místo jednoho monolitického jezera dat můžeme přistupovat k doménově orientovaným „data products“.
Například HR oddělení spravuje své směrnice a poskytuje je jako vektorizovaný datový produkt. Obchodní oddělení poskytuje produktová data. RAG aplikace pak může přistupovat k těmto decentralizovaným, ale standardizovaným datovým produktům. To zvyšuje přesnost (data spravuje vlastník domény) a bezpečnost (řízení přístupů na úrovni domény).
Cloudová analytika a zpětná vazba
Nasazením chatbota práce nekončí. Moderní cloudová analytika musí monitorovat samotný provoz AI:
-
Latence: Jak dlouho trvá retrieval a generování?
-
Cost Management: Sledování spotřeby tokenů.
-
Quality Assessment: Hodnocení relevance odpovědí (např. pomocí metodiky RAGAS – RAG Assessment).
Využitím nástrojů v rámci Azure Monitor a Application Insights můžeme v reálném čase ladit parametry vyhledávání a prompty modelu.
Od čistoty dat po halucinace
Při implementaci RAG se často setkáváme s tím, že data architecture ve firmách není připravena na nestrukturovaná data. Dokumenty jsou neaktuální, duplicitní nebo obsahují citlivé údaje, které by model neměl vidět (PII).
Řešením je implementace přísných ACL (Access Control Lists) na úrovni indexu – model by měl mít přístup pouze k těm dokumentům, ke kterým má oprávnění uživatel, který se ptá. To je standard, který Azure AI Search nativně podporuje.
AI je jen tak dobrá, jak dobrá jsou vaše data
Implementace RAG nad firemními daty není magie, ale sofistikovaná inženýrská disciplína. Vyžaduje pevnou ruku v oblasti správy dat (data governance), moderní infrastrukturu typu Data Lakehouse a hlubokou znalost cloudových služeb.
Ve společnosti Data Mind pomáháme klientům nejen s nasazením samotných modelů, ale především s budováním robustní datové základny, bez které AI nemůže efektivně fungovat. Ať už jde o optimalizaci datového skladu, migraci do cloudu nebo vývoj RAG aplikací na míru, klíčem k úspěchu je vždy architektura, která škáluje.