Pokud již máte kanceláře, fyzické sklady a provozní systémy, nastává čas pro skladování klíčového know-how. Tím není nic jiného než data - záznamy o zákaznících, partnerech i cenách.
Proč skladovat data
Data jsou v provozních systémech, je tedy otázka proč vůbec potřebujeme tvořit datové sklady. Tato potřeba nastane při rozvoji firmy, kdy marketing, finance a ostatní oddělení mají příliš mnoho dotazů, a brzdí tak provoz hlavních systémů. Situace, kdy je potřeba vybudovat datový sklad jsou tedy zejména následující:
- Provozní systémy jsou přetížené
- Provozní systémy nejsou nastaveny na to, aby skladovaly starší data
- Některá oddělení potřebují spouštět náročné dotazy nad velkým výsekem dat v pracovní době
Skladování dat nám jako přidanou hodnotu umožní lépe se zorientovat ve vlastním businessu a lépe poznat zákazníky i dodavatele. Data samozřejmě ze skladu nevyskáčou sama a nezačnou nám vyprávět svůj příběh spontánně. Umožní nám ale:
- Pohodlnější a bohatší reporting s více rozměry
- Analýzy podle potřeb každého oddělení v podniku
- Data mining – hledání skrytých souvislostí, předpovědi na úrovni zákazníka či zákaznické segmentace
Jsou ovšem také situace, kdy se doporučuje datový sklad nevytvářet. V případě, že na datový sklad nenavazují projekty, které zajistí jeho finanční návratnost, je konstrukce skladu velmi sporná. Datový sklad je také zcela pohřben ještě před svým zrodem, pokud nemá alokovány finanční zdroje a/nebo podporu nejvyššího vedení.
Projektový management
Projekt datového skladu obvykle stojí a padá s dobrým managementem. Projektový manažer stanoví, obvykle zcela nerealistický, časový rámec projektu. Tento rámec se prakticky nikdy nedodrží, neboť představuje ideální průchod čistými daty, s ideálními zaměstnanci, kteří nejezdí na dovolenou, nejsou nemocní a pracují jako roboti.
Vedle časového rámce je třeba stanovit role. Klíčovou rolí jsou nejen techničtí pracovníci, ale hlavně management, který projekt dostane přes všechna úskalí.
Projekt se doporučuje správně rozfázovat. Je totiž rozdíl, jestli při stavbě domu skončíte s dokončeným přízemím, nebo s nepoužitelnou stavbou bez oken. Stejně tak je projektový plán datového skladu rozfázován v tom smyslu, že je lépe dokončit nějaký tematický celek (například zákaznické objednávky), než se pustit s vervou do širého pole celého businessu.
Technologie datových skladů
Při volbě technologie byste měli zvážit, jak velké množství dat budete skladovat. Datový sklad se zásadně staví jako naddimenzovaný, se započtením velké rezervy. Tato rezerva musí zaručit nejen prostor pro růst dat na následujících pět let, ale také prostor pro dočasné tabulky potřebné během plnění či testování.
Pro “mikroskopické“ datové sklady s desítkami tisíc řádků se hodí nástroj Microsoft Access, který je k dostání za pár tisícovek samostatně, či v balíku Office. Dodavatelem „mikroskopických“ datových skladů je typicky lokální IT a výsledky jsou jen tak kvalitní, jako jejich realizátor.
Datové sklady střední velikosti tj. s miliony řádků volí mezi platformami, které jsou zadarmo a těmi placenými. Z open source dosáhli určité dospělosti zejména databáze MySQL a PostgreSQL. Mezi komerčními systémy jsou dobrou volbou například Microsoft SQL Server nebo Oracle Database. Stejně jako v jiných oblastech lidského života není produkt „zadarmo“ zdaleka vždy nejlevnější, a je třeba zvážit celkové náklady na jeho administraci. V některých případech je tak lepší spolehnout se na uživatelské pohodlí a podporu komerčních řešení.
Směrem k velkým datovým skladům se snižuje počet hráčů, kteří dokážou sklad dodat. Na českém trhu se v oblasti největších datových skladů etablovala Teradata, která nemá problémy se stamiliony řádků. Také ovšem účtuje v (mnoha) milionech korun.
Za několik let bude běžné vedle tradičních databází používat i nově vyvinutá Big data řešení, jejímž oblíbeným zástupcem je například Hadoop. V dnešní podobě má tento přístup zatím technická úskalí, která překonávají jen finančně a technicky nejvyspělejší firmy.
Poslední alternativou k tradičnímu datovému skladu jsou cloudová řešení, která se ovšem potýkají s nedůvěrou českých firem. Málokdo s manažerů dokáže rozhodnout o kompletním outsourcingu svých dat vzdálené společnosti do Spojených států. Na vině je nejen nerozhodnost, ale i nevyřešená legislativa a přece jen větší riziko úniku dat u systému, který ovládá třetí strana.
Nejdříve slovník
Po výběru technologie a dodavatele nastává fáze samotného budování datového skladu. Ač to zní možná divně, každá firma potřebuje datový slovník, definující její terminologii. Tento bod je někdy zanedbáván, nicméně je nesmírně důležitý. Předtím než budeme skladovat záznamy o zákaznících, je třeba si ujasnit, co to zákazník je. Ačkoli to vypadá jako nejjednodušší věc na světě, opak je pravdou. V mnohých organizacích ani netuší, že zákazník pro oddělení financí je něco zcela jiného, než pro marketing či prodej. Diskuse na téma: co zákazník je a není, bude ovšem zcela nevyhnutelná, pokud má dojít k sjednocení zmatených jazyků, reportů a čísel. Stejný problém nastane u marží, které jsou z účetního hlediska zcela jiné než z marketingového a prodejního pohledu apod. Nenechte se odradit zdánlivou nezáživností této fáze, ve skutečnosti v ní vzniká něco velmi cenného – firemní jazyk.
Fakta až v první řadě
Následuje fáze, ve které se mapují fakta ze zdrojových systémů, a definuje se podoba nového datového skladu. V podstatě je třeba si říci, co v datovém skladu bude. Na prvním místě jsou obvykle zákazníci a jejich transakce. K nim se přidává spousta informací typu adresy, emailu apod. Vedle zákazníků mapuje dobrý datový sklad i technické procesy, dodavatele, zaměstnance nebo fyzické sklady.
Datové modelování
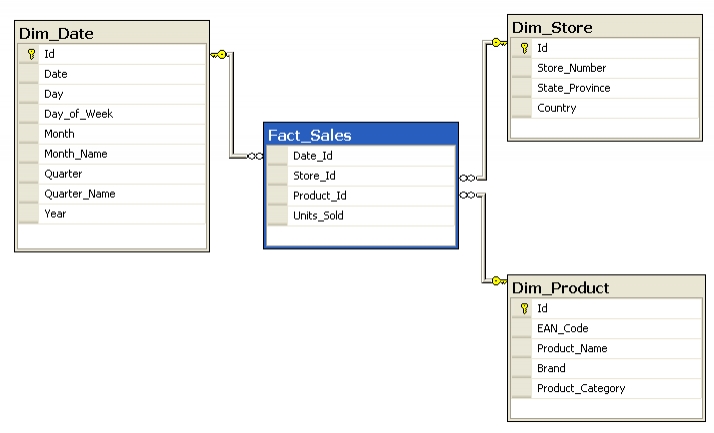
S obsahem se souběžně řeší schéma datového skladu tedy podoba tabulek a jejich propojení. Rozhoduje se také o tom, do jak daleké historie mají záznamy sahat a na jaké úrovni podrobnosti je budeme uchovávat. Schématu se obvykle říká datový model a tvoří ho mapa propojení tabulek, což nejlépe ilustrují obrázky. Každá tabulka musí mít svůj klíč, který jednoznačně identifikuje řádek. Schéma určuje propojení různých tabulek.
Obrázek: Schéma (datový model) částečně normalizované vzorové databáze Northwind od Microsoftu.

Na návrh modelu si můžete pozvat datového architekta, nebo jej řešit s většími či menšími obtížemi sami. Stejně jako u stavby domu je architekt téměř nezbytný, pokud sami neovládáte řemeslo. A stejné jako u projektu domu si můžete vybrat „katalogový“ předpřipravený model, nebo začít navrhovat na zelené louce. Druhý postup je mnohdy dražší.
Datový model by měl zajistit, že data o každém objektu v databázi budou mít speciální tabulku a že data se budou vždy vázat k primárnímu klíči, například k číslu zákazníka. Nejpoužívanějším sadám pravidel pro tvorbu databází se říká „normální forma“. V praxi se používá převážně třetí normální forma, což je relativně přísná metodika pro tvorbu datového modelu. Přísnost tohoto přístupu má za následek vznik mnoha desítek „koncepčně čistých“ tabulek vztahujících se ke každému myslitelnému faktu. Odměnou za tuto metodickou čistotu je vysoká rychlost databáze. Nevýhodou normální formy je určitá těžkopádnost pro uživatele daná typicky stovkami tabulek. Z přísných normálních forem poněkud slevují datové modely hvězdy, kde je k jedné tabulce navázáno množství číselníků a schéma tak připomíná hvězdnici, což opět ilustruji obrázkem.
Složité a normalizované modely datového skladu se hodí pro univerzální datové sklady, ke kterým bude přistupovat celá firma. Zjednodušené datové modely se naopak hodí tam, kde je potřeba pouze datové tržiště (data mart) pro jedno firemní oddělení nebo pro speciální účely.
Obrázek: Schéma typu hvězdice je vhodné pro lokální datamarty , (zdroj Wikipedia, autor SqlPac)
Ládujeme data
Když máme databázové schéma, je potřeba do něj „lít“ data. Tomuto procesu se říká ETL (extract-transform-load). To znamená, že některá data si ze zdrojových systémů musíme přeložit do jazyka datového skladu. Během procesu se obvykle eliminují duplicity, opravují zjevné chyby a data se dočišťují do použitelné podoby.
Testujeme a boříme
Když máme hotový prototyp datového skladu, je velmi vhodné výsledky z něho vystavit konfrontaci se stávajícími reporty. Dává nový sklad stejné výsledky? Pokud ne, nastává detektivní fáze, kdy musíme zjistit, v jakém kroku se nový datový sklad, či staré zdroje rozchází s realitou. Tato práce je hodná Sherlocka Holmese, jen je o něco méně oceňována.
Máme hotovo (?)
Stavba datového skladu vyžaduje mít v pořádku lidské, technické i manažerské zdroje. Odměnou za podařenou „stavbu“ je pak několik let relativního klidu a přesných dat. I ve fázi po stavbě datového skladu je však nutné držet nad daty pohotovost a všechny změny zdrojových systémů poctivě promítat do skladovaných dat. Ve firmách, kterým záleží na datech nejvíce, proto vznikla role datového stewarda, který dlouhodobě udržuje data v souladu s realitou.
Publikováno v časopise Computer
